
Title: Statistical Significance Analysis for Computer Vision Tasks
Statistical Significance Analysis for Computer Vision Tasks
Project Team :Sema Candemir and Dr. Yusuf Sinan Akgul.
Most computer vision problems are ill posed whose solution is not unique or does not exist or is not stable under perturbations on data. We presented a method which selects the statistically significant solution among other solutions. The method constricts the solution space of the problem by significance concept.
If the quality of the solutions are measured, it would be possible to compare them with each other. We are measuring the quality of the solutions using nonparametric statistical tests. Statistical significance is a probability value which is a measurement whether the outcome can happen accidentally or not. This term can be a measure for the quality of the solutions of ill posed problems. The measurement of the statistical significance is the p-value. It shows the probability of observance of the result among all other situations. To calculate the p values, the probability distribution (pdf) which the observance result was drawn should be known.The cumulative distribution which can be calculated from the pdf gives the p-values of the observed cost.
p-value = cdf ( observed statistic )
We choose the metric fusion as the initial test bed enviroment. We have combined the most popular stereo metrics (Sum of Absolute Differences, Sum of Squared Distance and Normalized Cross Correlation) to obtain better depth maps. The problem of the metric fusion is scale differences in metrics. Popular score normalization methos in information fusion are useless because of the differences in metric distributions.
|
SAD distribution fits Weibull distribution with parameters α=4,1 β=109,1 γ=109,2 |
SAD distribution fits Weibull distribution with parameters α=3,7 β=1957,4 γ=837,6 |
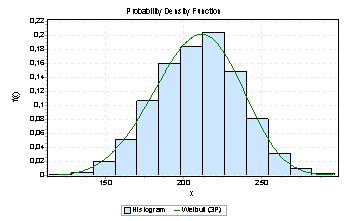
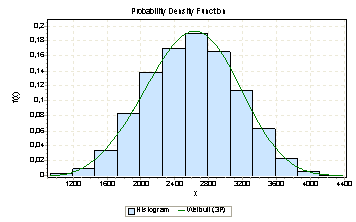
We have measured the quality of each cost for each metric and expressed them as p-values. Then we have selected the statistically more meaningful one for the correspondence procedure. The method behaves as nonparametric normalization technique for the costs from different distributions. We validated our claims using stereo test data with ground truth. First we calculate disparity maps for each image using fixed similarity metric (just SAD or SSD) and compared the results with the ground truth. Then we run proposed method, selecting the statistically significant metric for each local block. Table 1 shows the number of incorrect matches for fixed similarity metrics, and combined similarity metric. We summarized the results, for more result and detailed information please read our conference paper, A Nonparametric Statistical Approach for Stereo Correspondence, ISCIS07.
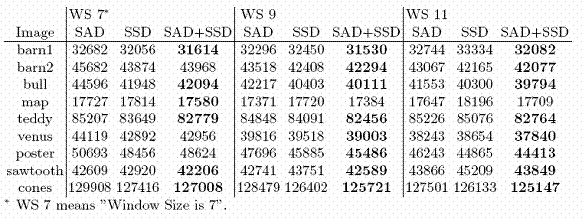
Table 1
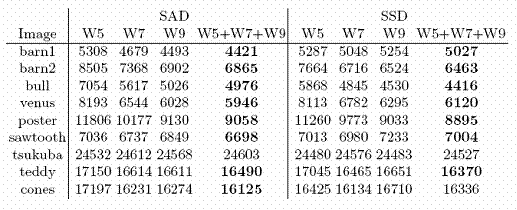
We also applied the method to adaptive window stereo correspondence. We measure the quality of cost of different window sizes for each local block. We calculate the probability distribution for wi by wi window sizes, i = 3,5,7, etc. Then for each local block, we calculate p-values which shows us the quality of that window size for that block. We select the most statistically significant window size for each local block. We test the method using ground truth values. We calculate disparity maps using fixed window size and using proposed method. Then compared the disparity maps with ground truth.
Now we are working on fusing data and smoothness costs using our method. The quality of each cost are measured and expressed as p-values. We expected to achieve more statistically significant results.










Segmentation results with different relative weights between data and smoothness costs. The one in red square is the best segmentation results with suitable relative weight. The result in blue square shows the better segmentation results using our method.
Publications- Sema Candemir, Yusuf Sinan Akgul, "Statistical Significance Based Graph Cut Regularization for Medical Image Segmentation", Turkish Journal Of Electrical Engineering & Computer Sciences, In Press
- Sema Candemir and Yusuf Akgul, "Statistical Significance Based Graph Cut Segmentation for Shrinking Bias", Int.Conf. on Image Analysis and Recognition, 2011, accepted.
- Sema Candemir, Yusuf Sinan Akgul: Adaptive Regularization Parameter for Graph Cut Segmentation. ICIAR (1) 2010: 117-126
- Sema Candemir and Yusuf Sinan Akgul. "A Nonparametric Statistical Approach for Stereo Correspondence", International Symposium on Computer and Information Sciences, 2007. [Poster (.pdf)]